پردازش دادههای حجیم با Apache Hadoop: سفری به دنیای کلاندادهها
⏳ مدت زمان مورد نیاز برای خواندن: حدود 20-25 دقیقه
آیا تا به حال به این فکر کردهاید که چگونه غولهای فناوری مانند گوگل و فیسبوک میلیونها گیگابایت داده را پردازش و تحلیل میکنند؟ یا شاید شما هم با چالش مدیریت و پردازش دادههای عظیم در پروژههای خود مواجه شدهاید. در دنیای امروز که دادهها به سرعت در حال افزایش هستند، Apache Hadoop به عنوان یک ابزار قدرتمند برای پردازش دادههای حجیم به کمک ما میآید.
در این مقاله، با Apache Hadoop آشنا خواهید شد و یاد خواهید گرفت که چگونه این ابزار میتواند پردازش دادههای کلان را سریعتر، دقیقتر و کارآمدتر کند. از مفاهیم اولیه تا مزایا، چالشها و کاربردهای واقعی، همه چیز را با هم بررسی میکنیم
 .
.
دادههای حجیم: چالشهای عصر دیجیتال
قبل از ورود به دنیای Hadoop، بیایید مفهوم دادههای حجیم (Big Data) را بررسی کنیم.
دادههای حجیم چیست؟
دادههای حجیم به مجموعهای از دادهها گفته میشود که به دلیل حجم زیاد، سرعت تولید و تنوع، مدیریت و پردازش آنها با ابزارهای سنتی امکانپذیر نیست.
این دادهها معمولاً شامل:
-
حجم بالا (Volume): میلیاردها رکورد یا ترابایت و پتابایت داده.
-
سرعت بالا (Velocity): تولید مداوم دادهها با سرعت زیاد.
-
تنوع (Variety): شامل دادههای ساختاریافته (مانند جداول) و غیرساختاریافته (مانند تصاویر، ویدیوها و متنها).
چالشهای پردازش دادههای حجیم
-
هزینه بالای ذخیرهسازی و پردازش.
-
پیچیدگی مدیریت دادهها.
-
نیاز به سرعت در پردازش و تحلیل.
-
تضمین صحت و امنیت دادهها
-
 .
.
Apache Hadoop چیست؟
Apache Hadoop یک چارچوب متنباز است که برای ذخیرهسازی و پردازش دادههای حجیم طراحی شده است. این چارچوب به سازمانها کمک میکند تا دادههای عظیم را به صورت توزیعشده و کارآمد مدیریت و تحلیل کنند.
ویژگیهای کلیدی Hadoop
-
متنباز: رایگان و قابل توسعه.
-
قابلیت مقیاسپذیری: میتوان به راحتی منابع سختافزاری و نرمافزاری را افزایش داد.
-
توزیعشده: دادهها در چندین گره (Node) ذخیره و پردازش میشوند.
-
پشتیبانی از انواع دادهها: دادههای ساختاریافته، نیمهساختاریافته و غیرساختاریافته.
-
مقاومت در برابر خطا: اگر یک گره دچار خطا شود، گرههای دیگر کار را ادامه میدهند
-
 .
.
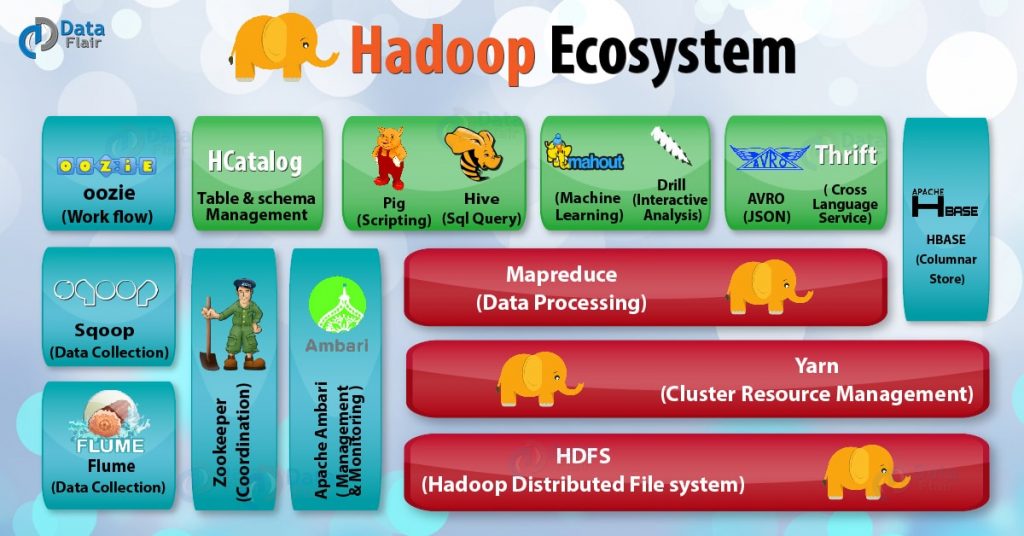
اجزای اصلی Apache Hadoop
Hadoop از چند جزء اصلی تشکیل شده است که هر کدام وظایف خاصی را انجام میدهند:
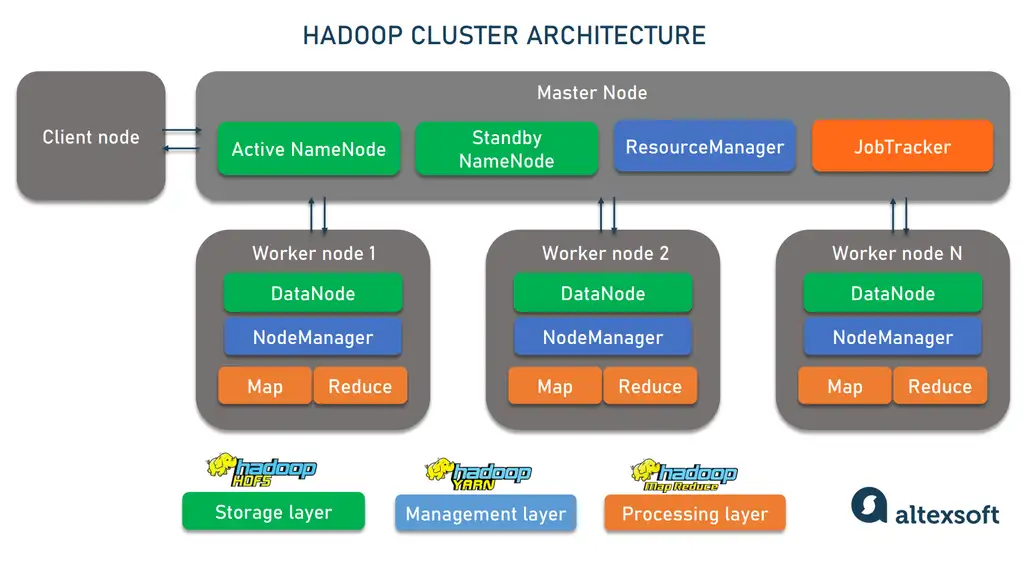
1. HDFS (Hadoop Distributed File System)
HDFS سیستم فایل توزیعشده Hadoop است که دادهها را به صورت بلوکهایی در گرههای مختلف ذخیره میکند. ویژگیهای HDFS:
-
ذخیرهسازی دادههای بزرگ در چندین گره.
-
تکرار دادهها برای جلوگیری از از دست رفتن آنها.
-
مدیریت کارآمد دادهها.
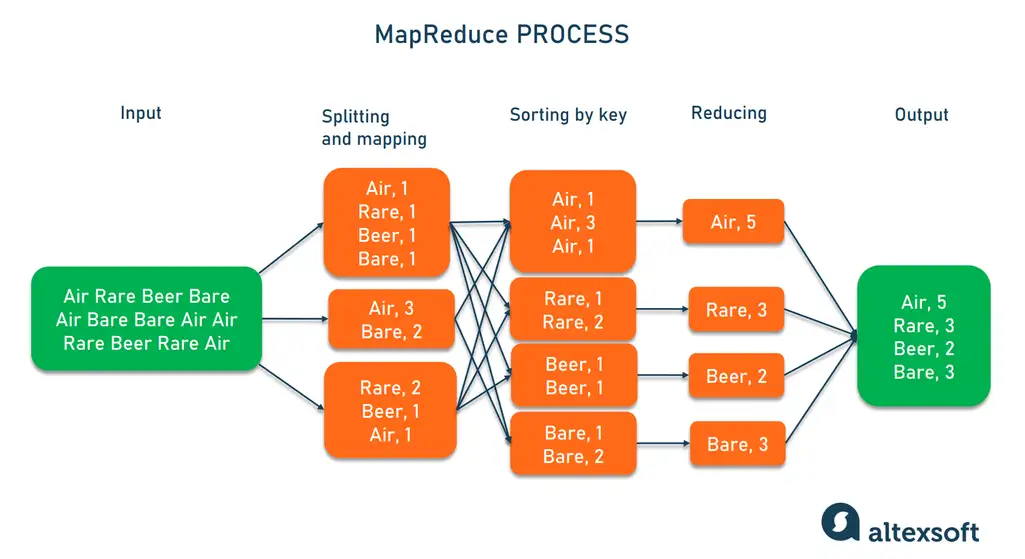
2. MapReduce
MapReduce مدل پردازشی Hadoop است که دادهها را به صورت موازی پردازش میکند. این مدل به دو مرحله اصلی تقسیم میشود:
-
Map: تجزیه دادهها به بخشهای کوچکتر.
-
Reduce: ترکیب و جمعبندی نتایج.
3. YARN (Yet Another Resource Negotiator)
YARN مسئول مدیریت منابع و زمانبندی وظایف در خوشه Hadoop است. این جزء به Hadoop اجازه میدهد چندین پردازش را به صورت همزمان اجرا کند.
4. Hadoop Common
این بخش شامل ابزارها و کتابخانههای عمومی مورد نیاز برای عملکرد اجزای دیگر Hadoop است
 .
.
مزایای استفاده از Apache Hadoop
-
پردازش دادههای بزرگ با سرعت بالا Hadoop با استفاده از پردازش موازی و ذخیرهسازی توزیعشده، دادههای حجیم را به سرعت پردازش میکند.
-
مقیاسپذیری میتوانید با اضافه کردن گرههای جدید، توانایی سیستم را افزایش دهید بدون اینکه نیاز به تغییرات اساسی در معماری باشد.
-
هزینه پایین استفاده از سختافزارهای ارزانقیمت (Commodity Hardware) امکانپذیر است.
-
انعطافپذیری Hadoop از انواع مختلف دادهها (متن، تصویر، ویدیو و غیره) پشتیبانی میکند.
-
امنیت و قابلیت اطمینان با استفاده از تکنیکهای تکرار دادهها و مدیریت خطا، خطر از دست رفتن دادهها به حداقل میرسد.
مراحل پردازش دادهها با Apache Hadoop
1. ورود دادهها
دادههای حجیم از منابع مختلف مانند پایگاه دادهها، فایلهای متنی، سنسورها یا APIها جمعآوری میشوند.
2. ذخیرهسازی دادهها در HDFS
دادهها به بلوکهایی تقسیم شده و در گرههای مختلف خوشه Hadoop ذخیره میشوند.
3. تجزیه و تحلیل دادهها با MapReduce
-
دادهها به فرآیند Map وارد میشوند و به واحدهای کوچکتر تقسیم میشوند.
-
نتایج حاصل از فرآیند Map وارد فرآیند Reduce میشوند تا دادهها ترکیب و نتیجه نهایی تولید شود.
4. بازیابی و نمایش نتایج
نتایج پردازش شده میتوانند به صورت گزارشها، نمودارها یا فایلهای خروجی نمایش داده شوند
 .
.
کاربردهای Apache Hadoop در دنیای واقعی
1. تجزیه و تحلیل دادههای تجاری
شرکتها از Hadoop برای تحلیل رفتار مشتریان، پیشبینی فروش و بهبود تجربه کاربری استفاده میکنند.
2. جستجوی اینترنتی
موتورهای جستجو مانند گوگل از Hadoop برای پردازش و ایندکسگذاری میلیاردها صفحه وب استفاده میکنند.
3. شبکههای اجتماعی
پلتفرمهایی مانند فیسبوک و توییتر از Hadoop برای پردازش دادههای کاربران و ارائه پیشنهادات شخصیسازیشده بهره میبرند.
4. تحقیقات علمی
مؤسسات تحقیقاتی از Hadoop برای پردازش دادههای ژنتیکی، شبیهسازیهای آب و هوا و تحلیلهای فضایی استفاده میکنند.
5. امنیت سایبری
Hadoop برای تحلیل لاگها و تشخیص تهدیدات امنیتی استفاده میشود.
چالشهای استفاده از Apache Hadoop
-
پیچیدگی پیادهسازی تنظیم و پیکربندی Hadoop ممکن است زمانبر و پیچیده باشد.
-
نیاز به مهارت فنی بالا برای استفاده از Hadoop، نیاز به دانش فنی در زمینه کلاندادهها و مدیریت خوشهها دارید.
-
زمانبر بودن MapReduce اگرچه MapReduce برای پردازش موازی طراحی شده است، اما در برخی موارد ممکن است زمانبر باشد.
-
مشکلات سختافزاری استفاده از سختافزارهای ارزانقیمت ممکن است باعث ایجاد خطاهای سختافزاری شود.
آینده Apache Hadoop
با ظهور فناوریهای جدید مانند Apache Spark و Cloud Computing، نقش Hadoop ممکن است تغییر کند. اما همچنان به عنوان یکی از ابزارهای پایهای برای مدیریت و پردازش دادههای حجیم مورد استفاده قرار میگیرد.
شرکتها در آینده به ترکیب Hadoop با فناوریهای پیشرفتهتری مانند یادگیری ماشین و هوش مصنوعی روی میآورند تا از قدرت دادهها به بهترین شکل بهرهمند شوند.
نتیجهگیری: مدیریت دادههای حجیم با Apache Hadoop
Apache Hadoop یک راهکار بینظیر برای مدیریت و پردازش دادههای حجیم است. این ابزار به شما امکان میدهد تا دادههای خود را به صورت کارآمد و مقرونبهصرفه مدیریت کنید و از آنها برای تصمیمگیریهای مهم استفاده کنید.
آیا آمادهاید تا با استفاده از Apache Hadoop، از قدرت دادهها برای پیشرفت کسبوکار یا پروژههای تحقیقاتی خود بهرهبرداری کنید؟ دنیای دادهها منتظر شماست!