الگوریتمهای یادگیری تقویتی در بازیهای ویدیویی
مقدمه
بازیهای ویدیویی از همان آغاز، به دنبال بهبود تجربه کاربر بودهاند. با پیشرفتهای هوش مصنوعی، اکنون امکان استفاده از الگوریتمهای یادگیری تقویتی (Reinforcement Learning یا RL) برای طراحی محیطهای تعاملیتر و هیجانانگیزتر وجود دارد. این الگوریتمها توانایی یادگیری از تجربه را به عاملهای بازی (Agents) میدهند، به طوری که بتوانند با بازیکنان در زمان واقعی تعامل کنند.
این مقاله بررسی میکند که چگونه RL به بهبود تجربه بازی کمک کرده و چالشها و فرصتهای این تکنولوژی را در صنعت بازی توضیح میدهد
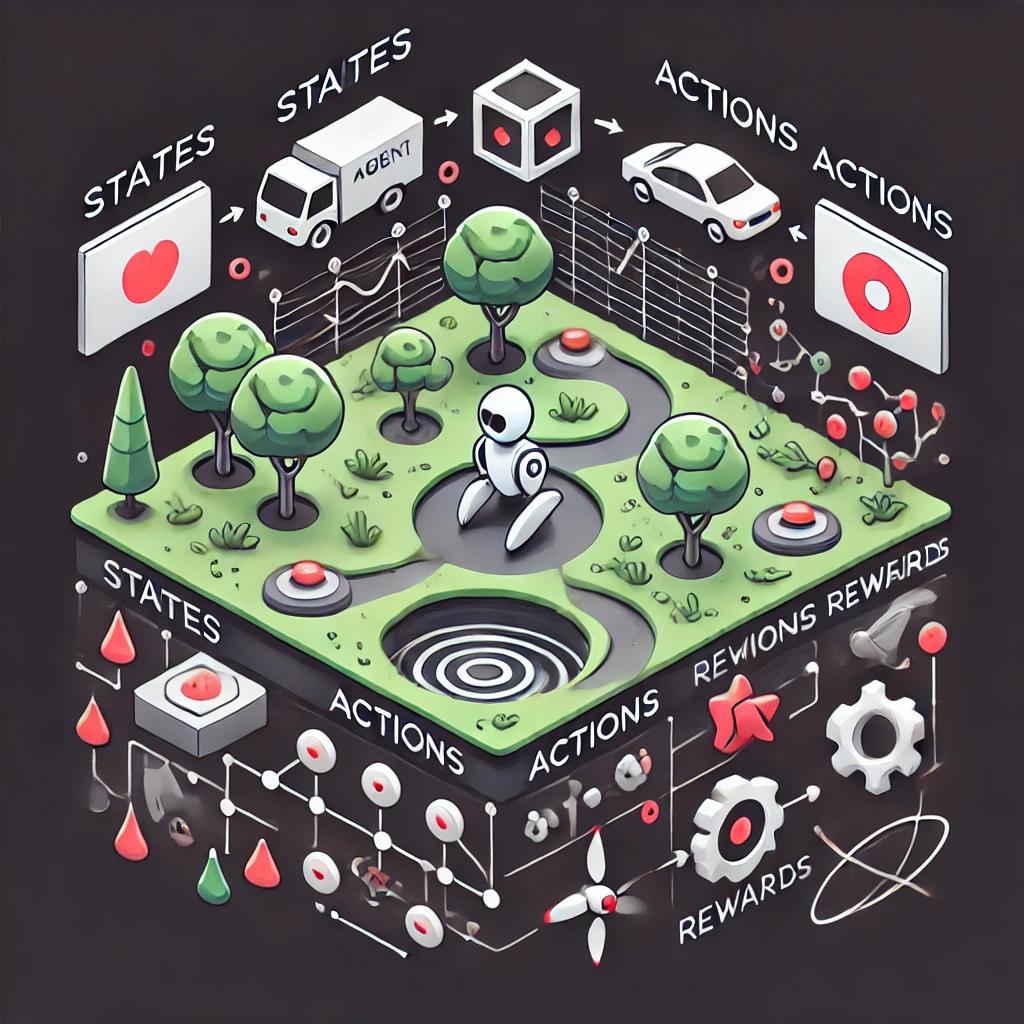
یادگیری تقویتی: تعریف و اصول
یادگیری تقویتی یک روش یادگیری است که در آن عامل (Agent) با محیط تعامل میکند و با توجه به پاداش یا تنبیه دریافتی، رفتار خود را بهینه میکند. اصول کلیدی RL عبارتند از:
-
وضعیت (State): نماینده وضعیت فعلی محیط است.
-
عمل (Action): تصمیم یا اقدام عامل.
-
پاداش (Reward): بازخوردی که عامل از محیط دریافت میکند.
این الگوریتم به طور گسترده در محیطهایی مانند بازیهای شطرنج، استراتژیک، و تیراندازی اول شخص (FPS) استفاده میشود.
تصویر: نموداری از تعامل بین عامل و محیط در RL.
کاربردهای اصلی RL در بازیهای ویدیویی
-
طراحی حریفهای پویا:
یکی از جذابترین کاربردهای RL، توسعه دشمنان هوشمند در بازیهاست. این دشمنان میتوانند رفتار خود را متناسب با سبک بازی بازیکن تغییر دهند.
تصویر: نمایی از یک شخصیت دشمن در حال یادگیری از حرکات بازیکن.
-
شبیهسازی محیطهای واقعگرایانه:
RL در بازیهایی مانند شبیهسازهای رانندگی یا پرواز به عاملها امکان میدهد تا رفتارهای طبیعیتری داشته باشند.
تصویر: محیط شبیهسازیشده یک بازی رانندگی با عاملهای RL.
-
آموزش و هدایت بازیکنان:
آموزشدهندههای مبتنی بر RL میتوانند مسیرهای بهینه برای بازیکنان تازهکار ارائه دهند.
تصویر: یک شخصیت آموزشی در بازی که مسیرها و تکنیکها را به بازیکن نشان میدهد.
-
تنظیم سطح دشواری:
RL میتواند سطح دشواری بازی را بر اساس مهارت بازیکن تنظیم کند تا تجربه بازی بهینه شود.
تصویر: نمودار سطح دشواری بازی در زمان واقعی بر اساس دادههای بازیکن
-
-

چالشهای استفاده از RL در بازیها
-
هزینه بالای محاسباتی:
الگوریتمهای RL برای یادگیری به منابع پردازشی زیادی نیاز دارند. این مسئله باعث میشود که در بازیهای پیچیده، هزینه توسعه افزایش یابد.
تصویر: یک مرکز داده در حال پردازش الگوریتمهای RL.
-
مشکلات تنظیم پاداش:
انتخاب سیستم پاداش مناسب در RL حیاتی است، زیرا طراحی نامناسب میتواند به رفتارهای غیرمنتظره منجر شود.
تصویر: نمایش رفتارهای نادرست عامل ناشی از تنظیم نادرست پاداش.
-
عدم پیشبینیپذیری رفتار عاملها:
عاملهای RL ممکن است رفتارهای پیشبینینشدهای از خود نشان دهند که میتواند تجربه بازی را تحت تأثیر قرار دهد.
تصویر: عامل بازی که تصمیمات غیرمنطقی در بازی گرفته است
-
-
-

مزایای آینده RL در صنعت بازی
-
بازیهای تعاملیتر:
استفاده از RL میتواند محیطهای بازی پویا و خلاقانهتری ایجاد کند.
تصویر: نمایی از یک بازی آیندهنگر که از RL استفاده میکند.
-
شخصیسازی بازیها:
RL به توسعهدهندگان اجازه میدهد تا تجربه بازی را برای هر بازیکن منحصر به فرد کنند.
تصویر: رابط شخصیسازیشده یک بازی که با استفاده از دادههای RL طراحی شده است
-
-
-

نتیجهگیری
الگوریتمهای RL توانستهاند انقلابی در طراحی و توسعه بازیهای ویدیویی ایجاد کنند. این تکنولوژی نه تنها تجربه بازیکنان را بهبود بخشیده، بلکه امکان خلق بازیهایی واقعگرایانهتر و تعاملیتر را فراهم کرده است. آینده بازیها، با استفاده از هوش مصنوعی و یادگیری تقویتی، هیجانانگیزتر از همیشه خواهد بود.